 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Hierarchical Distillation for Multimodal Emotion Recognition
Feb 04, 2026Human multimodal emotion recognition (MER) seeks to infer human emotions by integrating information from language, visual, and acoustic modalities. Although existing MER approaches have achieved promising results, they still struggle with inherent multimodal heterogeneities and varying contributions from different modalities. To address these challenges, we propose a novel framework, Decoupled Hierarchical Multimodal Distillation (DHMD). DHMD decouples each modality's features into modality-irrelevant (homogeneous) and modality-exclusive (heterogeneous) components using a self-regression mechanism. The framework employs a two-stage knowledge distillation (KD) strategy: (1) coarse-grained KD via a Graph Distillation Unit (GD-Unit) in each decoupled feature space, where a dynamic graph facilitates adaptive distillation among modalities, and (2) fine-grained KD through a cross-modal dictionary matching mechanism, which aligns semantic granularities across modalities to produce more discriminative MER representations. This hierarchical distillation approach enables flexible knowledge transfer and effectively improves cross-modal feature alignment. Experimental results demonstrate that DHMD consistently outperforms state-of-the-art MER methods, achieving 1.3\%/2.4\% (ACC$_7$), 1.3\%/1.9\% (ACC$_2$) and 1.9\%/1.8\% (F1) relative improvement on CMU-MOSI/CMU-MOSEI dataset, respectively. Meanwhile, visualization results reveal that both the graph edges and dictionary activations in DHMD exhibit meaningful distribution patterns across modality-irrelevant/-exclusive feature spaces.
* arXiv admin note: text overlap with arXiv:2303.13802
Merging and Evolution: Improving Convolutional Neural Networks for Mobile Applications
Mar 24, 2018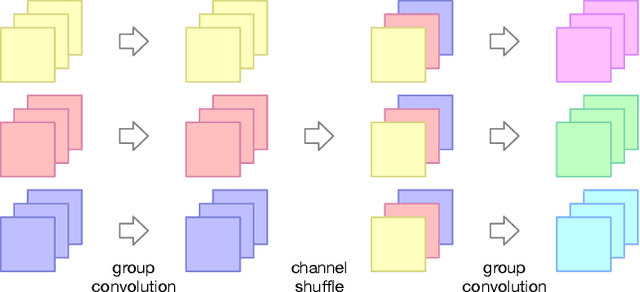
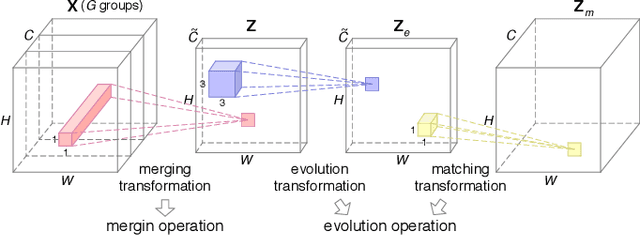
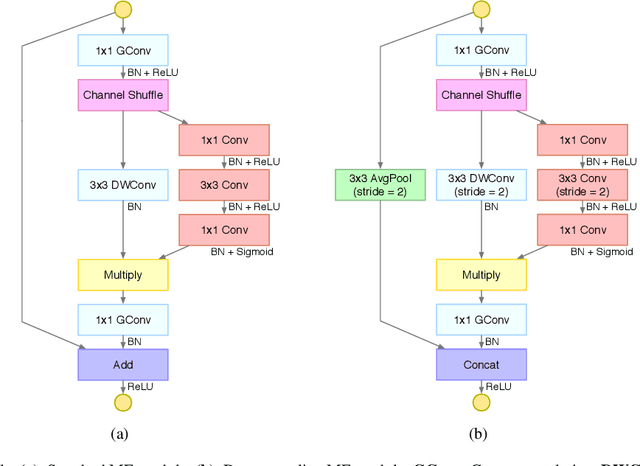
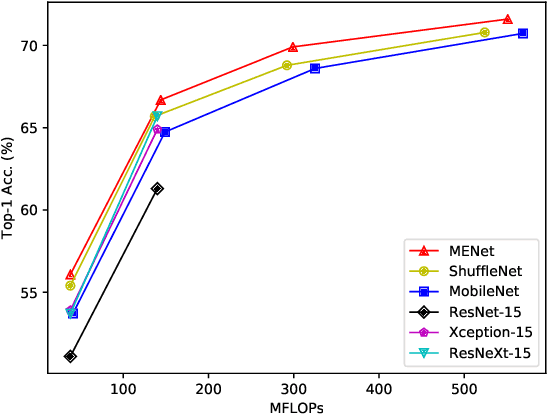
Compact neural networks are inclined to exploit "sparsely-connected" convolutions such as depthwise convolution and group convolution for employment in mobile applications. Compared with standard "fully-connected" convolutions, these convolutions are more computationally economical. However, "sparsely-connected" convolutions block the inter-group information exchange, which induces severe performance degradation. To address this issue, we present two novel operations named merging and evolution to leverage the inter-group information. Our key idea is encoding the inter-group information with a narrow feature map, then combining the generated features with the original network for better representation. Taking advantage of the proposed operations, we then introduce the Merging-and-Evolution (ME) module, an architectural unit specifically designed for compact networks. Finally, we propose a family of compact neural networks called MENet based on ME modules. Extensive experiments on ILSVRC 2012 dataset and PASCAL VOC 2007 dataset demonstrate that MENet consistently outperforms other state-of-the-art compact networks under different computational budgets. For instance, under the computational budget of 140 MFLOPs, MENet surpasses ShuffleNet by 1% and MobileNet by 1.95% on ILSVRC 2012 top-1 accuracy, while by 2.3% and 4.1% on PASCAL VOC 2007 mAP, respectively.